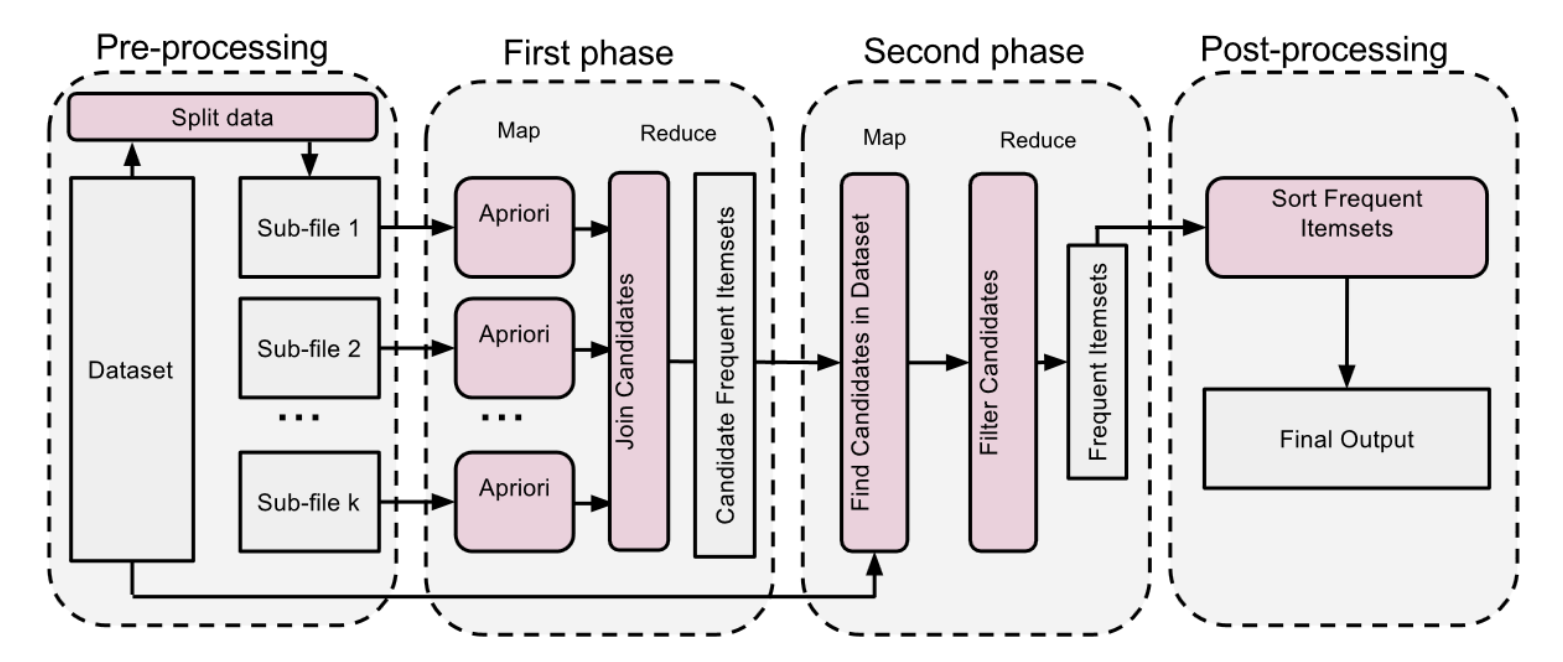
SON Algorithm
Key workings of SON (Savasere, Omiecinski & Navathe ) Algorithm:
First Pass - (finding candidate itemsets)
Break the dataset into smaller chunks that fit into the memory, for each chunk run the algo like apriori to find freq itemsets within that chunk.
(NOTE: we are not sampling the data rather processing the data into smaller parts)
One Second Pass - (validating candidates)
We count the occurance of all the candidates itemsets from step1 across the entire datasets.
- Only those itemsets that meet global support threshold are considered truly frequent.
Monotonicity Principle - If an itemset is frequent in entire dataset, it must be frequent in atleast one of the chunks. This help reduce search space because if an itemset is not frequent in any chunk, it cannot be frequent globally.
Algo:
Phase 1: Find local candidate itemset (Map-Reduce)
M1 - Each node(mapper) processes its data chunk & finds frequent itemsets using`Apriori`
R1 - Combine Results from all mappers to create a list of candidate itemsets
Phase 2: Find true frequent itemsets (Map-Reduce)
M2 - Each mapper counts occurance of candidates itemsets in its chunk.
R2 - Add up the counts from all the mappers. Itemsets meeting the support threshold are marked as frequent itemsets.
{kind=link}
Apriori Algorithm:
Pass 1: Read baskets and count in main memory the occurances of each single item
Items that appear at least s times are the frequent items, at the end of pass 1, after hte complete input file has been processed, check the count for each item.
So, pass 1 identifies frequent itemsets (support >=s) of size 1.
Pass 2: Read basket again and count in main memory only those pairs of items where both were found in pass1 to be frequent.
Requires -
-
Memory proportional to square of frequent items only (to hold count of pairs)
-
List of the frequent items from the first pass (so you know what must be counted)
Pairs of items that appear atleast s times are frequent pairs of size 2
At the end of pass2, check the count of each pair. If count>=s then that pair is frequent.
This process can be repeated for triplets and quadruplets etc.