Introduction
In the last decade, the world has undergone a digital transformation that’s touched every corner of our lives. From healthcare to finance, manufacturing to education, and beyond, digital data has become the lifeblood of industries, replacing stacks of paper and filing cabinets with streams of information. Today, our communications, transactions, and innovations are powered by this vast sea of data.
But with this surge of data comes a new frontier of challenges—and opportunities. How do we store it all? How do we process it efficiently? Most importantly, how do we unlock its potential to create value? These are the questions data engineering is here to answer.
Defining Data Engineering
Data Engineering is the development, implementation, and maintainence of systems and processes that take in raw data and prodice high-quality, consistent information that supports downstream use cases, such as analysis and machine learning. Data Engineering is the intersection of security, data management, dataops, data architecture, orchestration, and software engineering.
- Joe Reis (author of Fundamentals of Data Engineering)
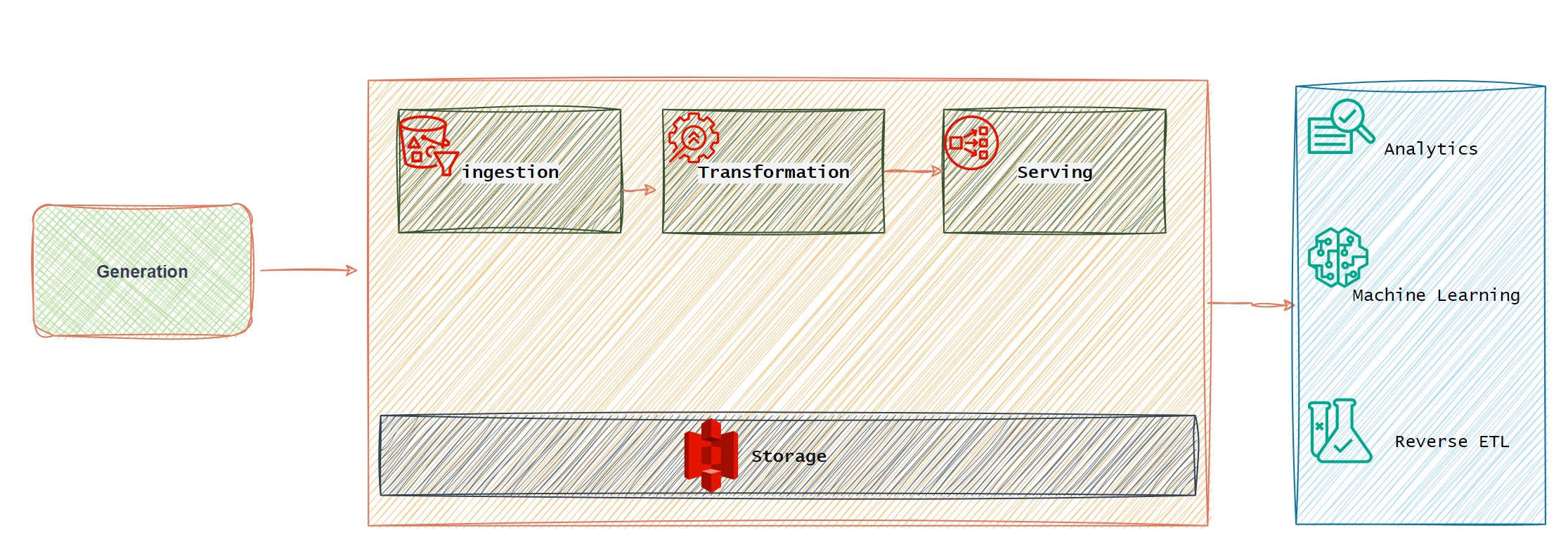
A common data pipeline (i.e the combination of architecture, systems and processes that move data through the stages of data engineering lifecycle) can be imagined as below.
Stakeholders and Business Value
“In business, value is created when you deliver something your customers didn’t know they needed but can’t live without." – Eric Ries
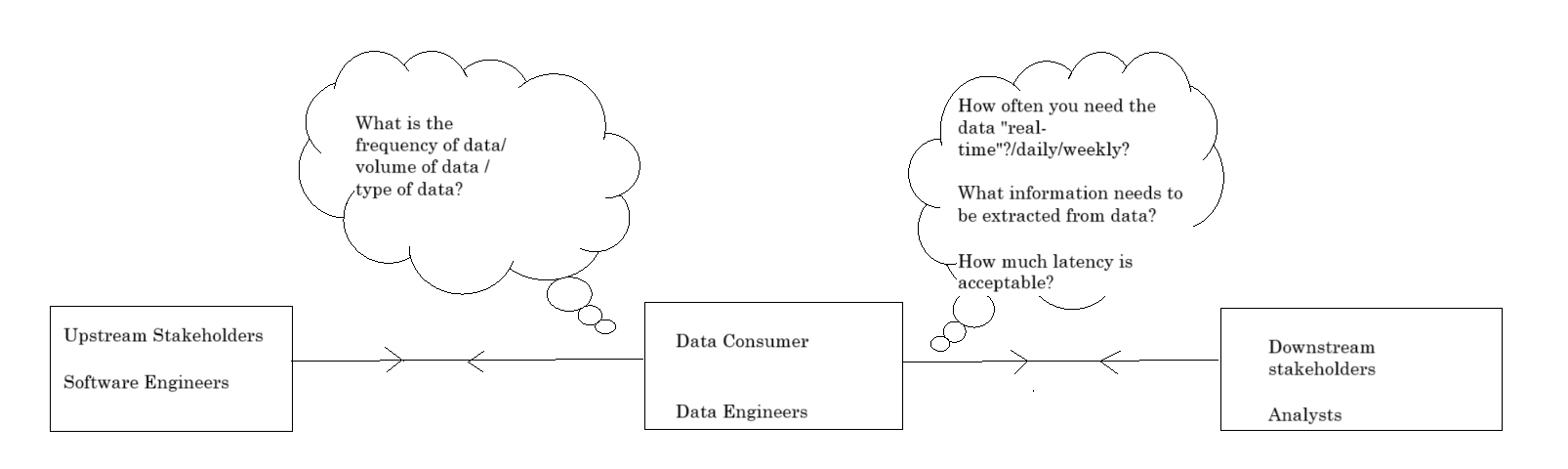
The role of a data engineer is to gather raw data, transform it into something useful, and make it accessible for downstream use cases. To be successful in this field, one must understand the needs of downstream users such as machine learning engineers, data scientists, sales professionals, and those in product or marketing roles. It is crucial for data engineers to engage with the overall strategy of their company. This awareness helps in identifying the business value that can be derived from the data they provide and understanding the business metrics or stakeholders that are important to the organization.
In addition to downstream stakeholders, we also need to consider upstream stakeholders—those responsible for developing and maintaining the source systems from which you extract raw data. Typically, these upstream stakeholders are the software engineers who create the source system you are utilizing. They could be engineers within your own organization or developers from a third-party source that you are pulling data from. It’s essential to communicate with the owners of the source systems to gather insights on expected volume, frequency, and format of the generated data. Additionally, understanding factors like data security and regulatory compliance is crucial for managing the data engineering lifecycle effectively. Building a strong relationship with the owners of the source systems can greatly benefit your work. By fostering open communication, you can collaborate with them to influence the way raw data is provided. They can also inform you ahead of time about potential disruptions in data flow or any changes, such as modifications to the data schema.
Requirements
Now requirements can be of several types -
-
Business requriement - i.e High level goals of the business eg: grow revevnue, increase user base.
-
Stakeholder requirement - needs of individuals within the organization.
-
System requirements - functional and non-functional requirements
3.1 Functional requiremnts - What the system needs to be able to do? Provide regular updates to a database and alert user about an anomaly in the data.
3.2 Non-Functional requirements - How the system accomplishes what it needs to do? Technical specifications of an ingestion ororchestration or storage approach.
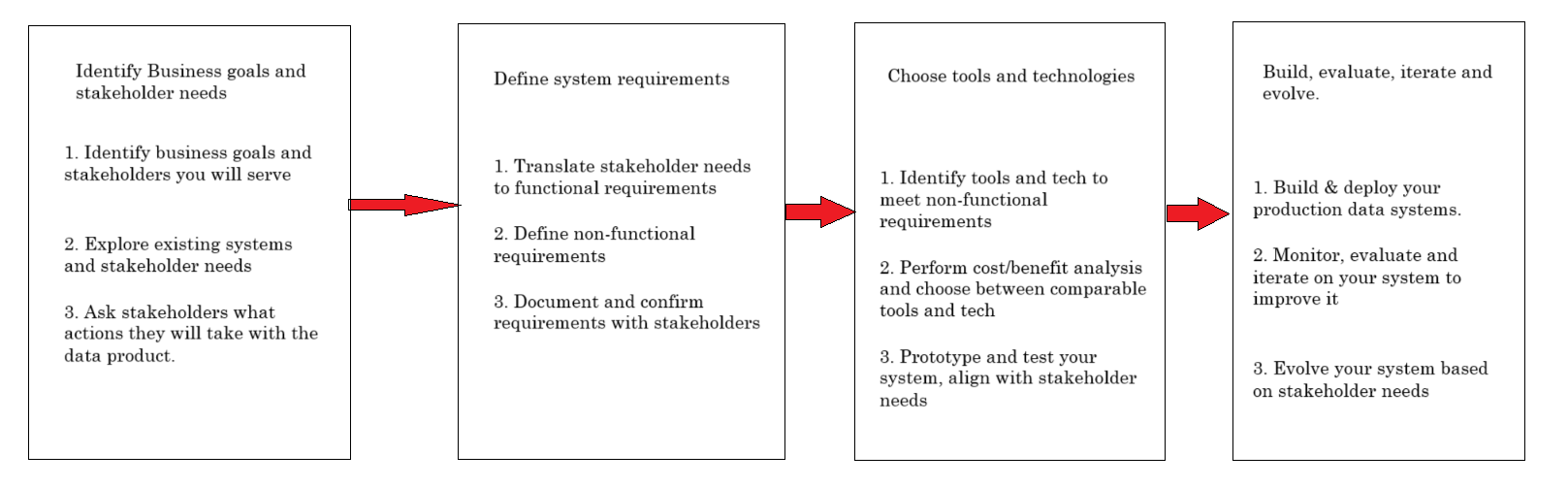
To develop any data system effectively, you must begin with a comprehensive set of requirements. These requirements can span a wide range, from high-level business and stakeholder objectives to specific features and attributes of the data products you intend to provide. You should also account for technical specifications, including the necessary memory and storage capacity for your computational and database resources. Additionally, consider any cost constraints, as well as security and regulatory requirements that may apply.
The initial and most crucial step in any data engineering project is to gather these requirements. Typically, these requirements will originate from your downstream stakeholders—those who aim to achieve their objectives through your work. However, it’s important to note that stakeholders often express their needs in terms of business goals rather than concrete system requirements. As a data engineer or analyst, it’s your responsibility to translate these business needs into actionable requirements for your system.
Key Elements of Requirements Gathering -
- Learn what existing data systems or solutions are in place.
- Learn what pain points or problems there are with existing solutions
- Learn what actions stakeholders plan to take with the data
- Identify any other stakeholders you’ll need to talk to if you’re still missing information.
To summarize -
The Data Engineering Lifecycle
Stage 1: Data Generation in Source Systems
The first stage in the data engineering lifecycle involves generating data from various source systems. As a data engineer, your role often includes consuming data from diverse sources. For instance, in an e-commerce company, you might build pipelines that ingest sales data from internal databases, product information from files, social media insights via APIs, or market research datasets from data-sharing platforms. Additionally, IoT devices like GPS trackers may provide real-time location and movement data for delivery updates.
While these systems are typically developed and managed by software engineers, external vendors, or third-party platforms, understanding their functionality is crucial. This knowledge ensures the data pipelines you design can seamlessly integrate and process the data they produce, forming a robust foundation for downstream data workflows.
Stage 2: Ingestion - Batch vs. Streaming
As a data engineer, the first major task is data ingestion—moving raw data from source systems into your data pipeline for further processing. In my experience, the source systems and ingestion processes often pose the most significant bottlenecks in the data engineering lifecycle. Collaborating early with source system owners to understand how these systems generate data, how they evolve, and how changes impact downstream systems can help mitigate these challenges.
Data Ingestion Patterns
When designing ingestion processes, a critical decision is the frequency of data ingestion. You have two primary patterns to choose from:
- Batch Ingestion
Data is ingested in large chunks, either on a fixed schedule (e.g., daily or hourly) or triggered when the data reaches a certain size threshold. Batch processing has been the traditional default and remains practical for many use cases like:
- Model training
- Analytics
- Weekly or monthly reporting For instance, you could process an entire day’s worth of website clicks or sensor measurements in a single batch.
- Streaming Ingestion
Data is ingested and processed continuously in near real-time, typically with delays of less than a second. Streaming ingestion is ideal for use cases requiring:
- Real-time anomaly detection
- Dynamic dashboards
- Time-sensitive operations like fraud detection Tools like event-streaming platforms (e.g., Kafka) or message queues facilitate this type of ingestion.
Choosing Between Batch and Streaming
While streaming is gaining popularity, it’s not universally the best choice. Consider the following trade-offs when deciding:
- Business Needs : What value does real-time data provide over batch data for your specific use case?
- Cost and Complexity : Streaming ingestion often demands higher investments in tools, time, and maintenance.
- Pipeline Impact : How will your choice affect downstream processing and overall architecture?
Often, batch and streaming ingestion coexist in a pipeline. For instance:
- Real-time streaming ingestion may be used for anomaly detection, while
- The same data is later processed in batches for model training or reporting.
Additional Ingestion Considerations
Beyond batch vs. streaming, there are additional nuances:
- Change Data Capture (CDC) : Ingestion triggered by data changes in the source system.
- Push vs. Pull : Whether data is pushed from the source system or actively pulled into the pipeline.
While batch ingestion remains effective for many scenarios, streaming should only be adopted when its trade-offs align with clear business value. A hybrid approach is often the most practical, ensuring the right balance between efficiency and real-time capability.
Stage 3: Storage
Data storage is a crucial pillar in the data engineering lifecycle, influencing the performance, scalability, and cost of your systems. Whether you’re managing files on your laptop, interacting with apps on your smartphone, or backing up data to the cloud, you’re constantly engaging with various storage systems. These everyday interactions highlight the functionality, performance, and limitations of storage solutions—concepts that are equally critical in a data engineer’s work.
Understanding the Hierarchy of Data Storage
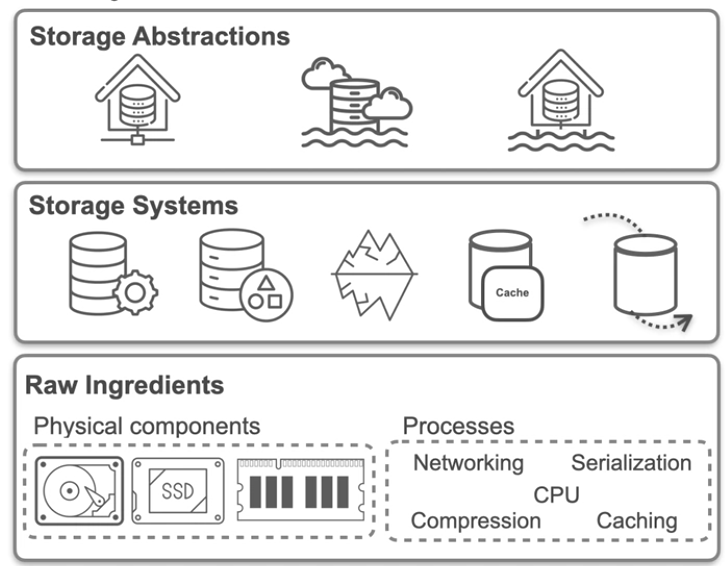
Storage can be conceptualized as a hierarchy with three main layers:
- Raw Ingredients
The foundation of data storage includes:
- Magnetic Disks : Affordable and still widely used for bulk storage.
- Solid-State Drives (SSDs) : Faster and more durable but pricier than magnetic disks.
- RAM (Random Access Memory) : Ultra-fast but volatile and significantly more expensive than SSDs. Non-physical components like networking, serialization, compression, and caching also play vital roles.
- Storage Systems
Built on raw ingredients, these systems provide structured ways to manage and retrieve data:
- Database Management Systems (DBMS)
- Object Storage Platforms like Amazon S3
- Specialized systems such as Apache Iceberg or Hudi for data versioning and management.
- Storage Abstractions
At the top, abstractions like data warehouses , data lakes , and data lakehouses combine storage systems to meet high-level needs:
- Data Warehouses : Optimized for structured data and analytics.
- Data Lakes : Handle large volumes of raw, unstructured data.
- Lakehouses : A hybrid approach that blends the benefits of both.
As a data engineer, you’ll likely spend most of your time working with storage abstractions, configuring parameters to meet requirements for latency, scalability, and cost . However, understanding the underlying components is crucial for optimizing system performance.
The Role of Physical Storage in Modern Architectures
Modern architectures leverage a mix of magnetic disks , SSDs , and RAM to handle data at different processing stages. For example:
- Data might first be ingested into magnetic storage for cost efficiency.
- Frequently accessed data might move to SSDs for faster retrieval.
- Intermediate processing often occurs in RAM , leveraging its speed.
Cloud storage systems distribute data across multiple clusters and data centers, incorporating technologies like serialization and compression to ensure efficient storage and retrieval.
Common Pitfalls in Data Storage
Failing to understand storage system intricacies can lead to costly mistakes. For instance:
- A team once opted for row-by-row data ingestion into a data warehouse, resulting in massive costs and delays. Switching to a bulk ingestion approach resolved the issue, but only after wasting significant resources.
Why Storage Savvy Matters
To avoid such pitfalls, it’s essential to grasp not just the high-level abstractions but also the inner workings of your storage solutions. This understanding will help you make informed decisions about:
- When to use batch vs. streaming ingestion
- The trade-offs between latency and cost
- How to balance storage efficiency with performance
Stage 4: Queries, Modeling, and Transformations
The transformation stage is where a data engineer truly adds value, converting raw data into meaningful and usable formats for downstream users. Unlike the ingestion and storage stages, which primarily involve moving and housing raw data, transformation directly impacts how effectively data can be leveraged for business insights.
The Role of Transformation in Adding Value
Imagine your downstream users:
- Business Analysts need clean, well-organized data to generate reports, like daily sales across products. They may require fields such as customer IDs, product names, prices, and timestamps, formatted for quick and efficient querying.
- Data Scientists or ML Engineers rely on preprocessed data for building models. Your role is to prepare this data by engineering features, cleaning, or aggregating it to make it directly usable for predictive tasks.
The Three Components of Transformation
Transformation isn’t a single process—it comprises three interconnected activities: queries, modeling, and transformation.
- Queries
Querying retrieves data from storage systems, often using SQL . Effective queries clean, join, and aggregate data across datasets.
- Poorly written queries can lead to issues such as:
- Row Explosion : An unexpected increase in rows during joins.
- Performance Bottlenecks : Slow queries can delay downstream processes.
- As a data engineer, understanding how queries work under the hood helps you optimize their performance and avoid architectural pitfalls.
- Poorly written queries can lead to issues such as:
- Data Modeling
Data modeling involves structuring data to reflect real-world relationships and business needs.
- Example: A normalized database might store product info, order details, and customer data in separate tables. To help analysts, you may need to denormalize this data, combining tables into a format optimized for reporting.
- A good model aligns with business logic and stakeholder needs, ensuring clarity and usability. For instance, the term “customer” might have different meanings across departments, requiring clear definitions during the modeling process.
- Data Transformation
Transformation manipulates and enhances data to make it ready for use:
- In-flight transformations : Add timestamps or map data types during ingestion.
- Post-ingestion transformations : Standardize formats, enrich records, or compute derived fields.
- Downstream transformations : Denormalize data, aggregate for reporting, or featurize for machine learning models.
The Iterative Nature of Transformation
Data transformation isn’t a one-time activity—it occurs throughout the data lifecycle:
- Source System : Data might be partially transformed (e.g., adding timestamps).
- Pipeline : Transformations happen during ingestion, post-ingestion, and before data is consumed.
- End-Use : Data is further refined for reporting, analytics, or model training.
Why Transformation Matters
Well-executed transformations ensure:
- Faster queries for analysts.
- Reliable data pipelines for machine learning.
- Accurate insights for decision-making.
However, poorly managed transformations can lead to inefficiencies, inaccuracies, or unnecessary costs.
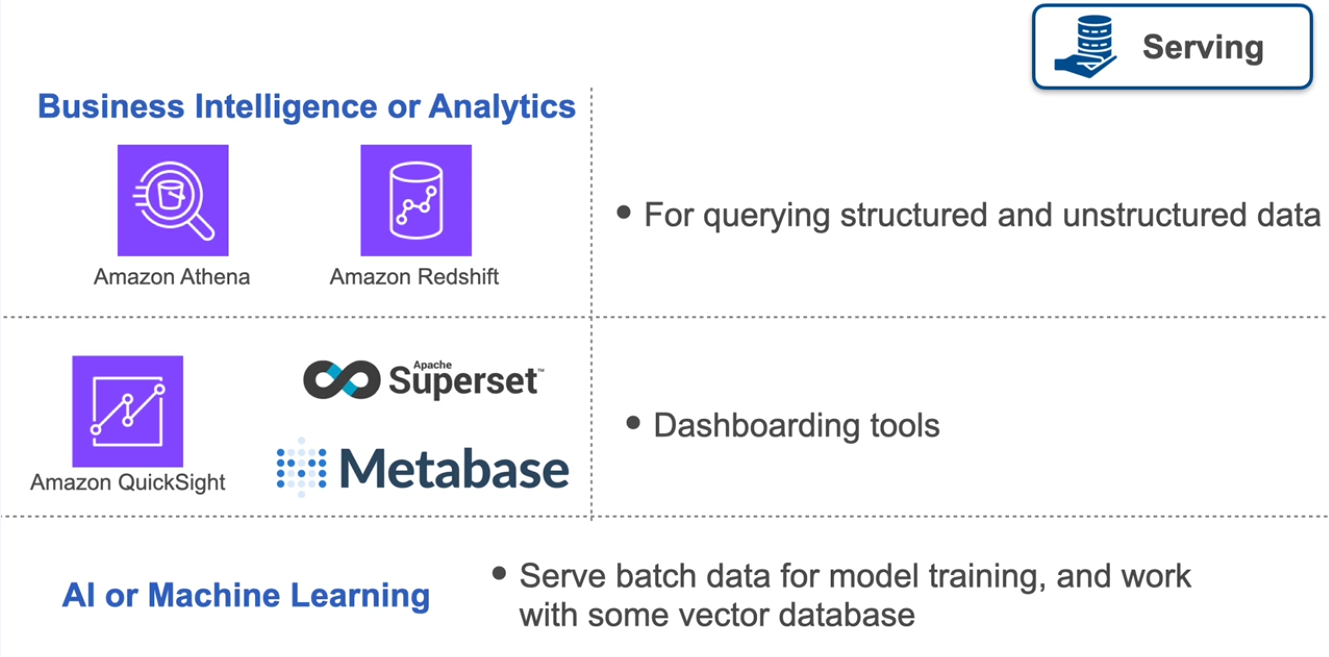
Stage 5: Serving
The serving stage is the culmination of the data engineering lifecycle, where data is made available for stakeholders to extract actionable insights and drive business value. This stage goes beyond simply providing access to data—it’s about tailoring data delivery to specific use cases, such as analytics, machine learning, or operational workflows.
End-Use Scenarios for Data Serving
Serving data can take many forms, depending on the needs of stakeholders. Here’s an overview of the primary scenarios:
- Analytics
Analytics involves identifying insights and patterns in data, often categorized into three types:
- Business Intelligence (BI) : Analysts use BI to explore historical and current data via dashboards or reports. As a data engineer, you’ll serve data that powers these tools, enabling stakeholders to monitor trends like sales performance or customer behavior.
- Example: A spike in product returns prompts an analyst to investigate patterns using dashboards and SQL queries.
- Operational Analytics : Focused on real-time monitoring, operational analytics supports immediate action. For instance, you might serve event data from application logs to a dashboard that tracks e-commerce platform uptime.
- Embedded Analytics : Customer-facing dashboards and applications provide external users with insights, like a bank app showing spending trends or a smart thermostat app displaying historical temperature metrics. Your role involves serving both real-time and historical data for these applications.
- Machine Learning (ML)
Serving data for ML use cases adds complexity, requiring specialized workflows:
- Feature Stores : Enable efficient and reusable data preparation for model training.
- Real-Time Inference : Serve data to ML models for instant predictions.
- Metadata and Lineage Tracking : Support the management of data history and dependencies. These tasks ensure seamless integration of data into machine learning pipelines.
- Reverse ETL
Reverse ETL involves feeding transformed data back into source systems to enhance business processes.
- Example: After ingesting customer data from a CRM system, you might transform it in a data warehouse and use it to train a lead-scoring model. The model’s output is then returned to the CRM, enriching the original client records with predictive insights.
While the term “reverse ETL” may not fully describe the process, this practice is increasingly common in data workflows and highlights how data can create a feedback loop into operational systems.
Tailoring Data Delivery to Stakeholder Needs
The value derived from serving data varies by stakeholder:
- Business Analysts : Need well-structured data for ad hoc queries, dashboards, and reports.
- Operational Teams : Require real-time insights to monitor systems and respond swiftly to issues.
- Data Scientists and ML Engineers : Depend on curated datasets, feature stores, and real-time data for model training and inference.
- External Users : Rely on embedded analytics for actionable insights via user-facing applications.
Key Considerations for Data Serving
To serve data effectively, you must:
- Optimize latency for real-time use cases.
- Balance scalability and cost to meet organizational needs.
- Ensure data integrity and lineage for accurate and trustworthy insights.
The Undercurrents of Data Engineering Lifecycle
Security
Security is a critical consideration for data engineers, as you are entrusted with sensitive and proprietary information.
Key Principles of Data Security
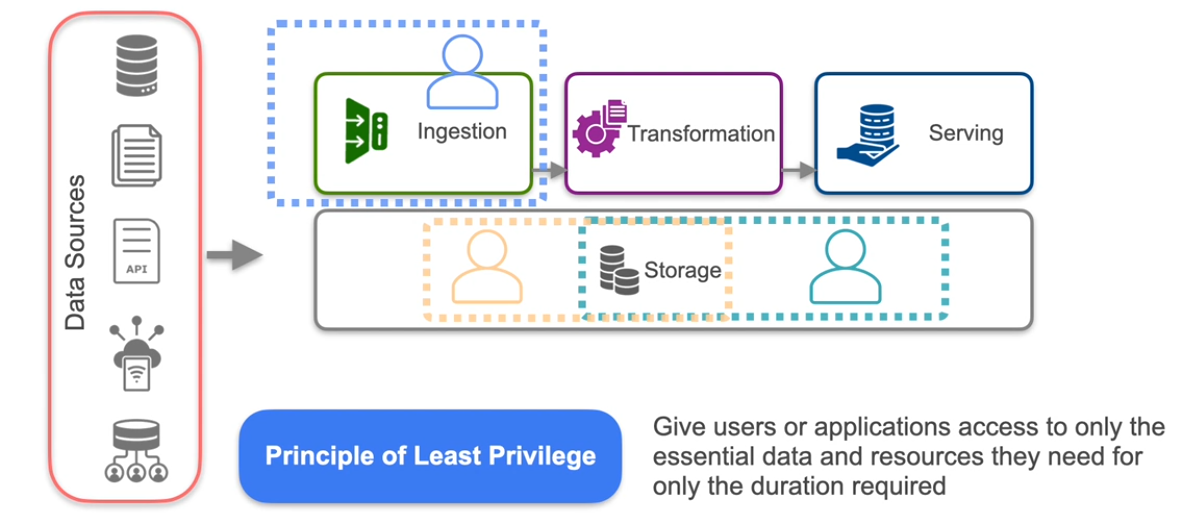
- Principle of Least Privilege
Grant users or applications access only to the resources and data they need, and only for the time they require it. This principle applies not just to others but also to you:
-
Avoid operating with root or administrator permissions unless absolutely necessary.
-
Restrict sensitive data access to only those with a clear, essential need.
-
- Minimize Data Sensitivity Risks
- Avoid ingesting sensitive data if it is not necessary for the system’s function. This eliminates the risk of accidental leaks.
- Mask or anonymize sensitive data when it must be ingested, ensuring its visibility is tightly controlled.
- Cloud-Specific Security
In cloud environments, security involves understanding and applying:
- Identity and Access Management (IAM) roles and permissions.
- Encryption methods to protect data in transit and at rest.
- Networking protocols to secure connections and prevent unauthorized access.
- Adopt a Defensive Mindset
- Be cautious when handling credentials and sensitive data.
- Anticipate potential attack and leak scenarios.
- Design systems with proactive defenses against phishing, social engineering, and accidental exposure.
Common Security Pitfalls
- Exposed Resources : Leaving an AWS S3 bucket, server, or database unintentionally accessible to the public internet is a recurring issue. Avoid this by ensuring configurations are secure by default.
- Human Error : Many security breaches stem from people ignoring best practices, sharing passwords insecurely, or falling for phishing scams.
Data Management
Data management is the backbone of successful data engineering, ensuring that data is a valuable business asset throughout its lifecycle. Effective data management enhances the value, usability, and reliability of data for all stakeholders.
According to the Data Management Book of Knowledge (DMBOK), data management is the development, execution, and supervision of plans, programs, and practices that deliver, control, protect, and enhance the value of data and information assets throughout their life cycles.
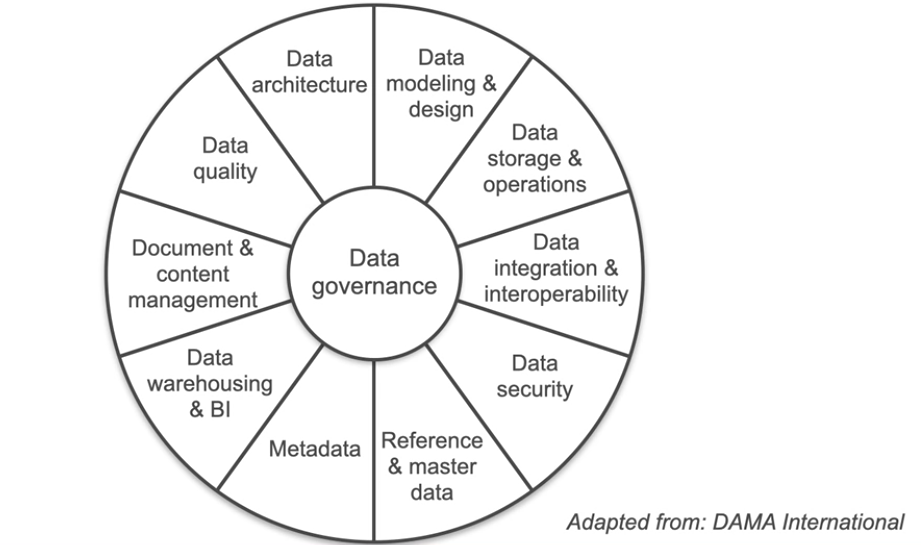
While Data Engineers don’t deal with all aspects of Data Management and rather share responsibilities with IT, Software Engineers etc. But Data Engineer do play important roles in Data Governance which ensures the quality, integrity, security, and usability of an organization’s data. It covers:
- Data Security and Privacy : Protect sensitive data from unauthorized access (covered in the previous video).
- Data Quality : High-quality data is essential for informed decision-making and operational efficiency. As a data engineer, ensuring data quality involves making sure that data is:
- Accurate : Free of errors or inconsistencies.
- Complete : Contains all required information.
- Discoverable : Easily located and accessed by stakeholders.
- Timely : Delivered when needed
Whereas low-quality data leads to wasted resources, faulty decisions, and loss of trust in data systems.
Data Architecture
Building a robust data architecture requires adhering to key principles that ensure the system is scalable, reliable, cost-efficient, and secure. Here’s a breakdown of these principles:
1. Choose Common Components Wisely
- Definition : Common components are shared parts of your architecture used across teams and projects.
- Why It Matters : A well-chosen component should:
- Offer the right features for individual projects.
- Facilitate collaboration and consistency across teams.
- Example : Selecting a cloud data warehouse that supports both analytics and machine learning workloads.
2. Plan for Failure
- Definition : Design systems to handle unexpected failures gracefully.
- Why It Matters : No system is fail-proof, but a robust architecture:
- Minimizes downtime.
- Ensures smooth recovery during disruptions.
- Implementation : Use redundancy, backups, and failover mechanisms.
3. Architect for Scalability
- Definition : Build systems that can scale up or down based on demand.
- Why It Matters :
- Scale Up : Handle peak loads efficiently.
- Scale Down : Save costs during low-demand periods.
- Implementation : Use scalable cloud services and auto-scaling configurations.
4. Architecture as Leadership
- Definition : A good architecture reflects thoughtful leadership.
- Why It Matters : Even as a data engineer, adopting an architect’s mindset:
- Helps you mentor others.
- Prepares you for future roles as a data architect.
- Tip : Seek mentorship from experienced architects to grow your leadership skills.
5. Always Be Architecting
- Definition : Architecture is an ongoing process, not a one-time task.
- Why It Matters :
- Business needs evolve, and your architecture must adapt.
- Regular evaluations ensure the system remains relevant and effective.
- Action Plan : Continuously review and refine your system design.
6. Build Loosely Coupled Systems
- Definition : Design systems where components function independently and can be swapped out easily.
- Why It Matters :
- Reduces dependency on specific tools or technologies.
- Facilitates quick adaptations to new requirements.
- Example : Using APIs to connect components rather than hard-coding dependencies.
7. Make Reversible Decisions
- Definition : Design systems that allow for changes without major overhauls.
- Why It Matters :
- Avoids locking into specific tools or architectures.
- Enables flexibility as business needs evolve.
- Implementation : Favor modular designs and configurable components.
8. Prioritize Security
- Definition : Security is integral to every aspect of architecture.
- Why It Matters :
- Protects sensitive data and systems.
- Mitigates risks from breaches and unauthorized access.
- Key Practices :
- Principle of least privilege.
- Zero-trust security models.
- Regular audits and updates.
9. Embrace FinOps
- Definition : FinOps integrates financial efficiency with operational excellence.
- Why It Matters :
- Cloud systems are pay-as-you-go, and costs can escalate without proper oversight.
- Aligns financial goals with technical decisions.
- Implementation :
- Monitor and optimize resource usage.
- Automate scaling to balance cost and performance.
DataOps
Similar to its DevOps counterpart, DataOps aims to improve the development process and quality of data products. It is a set of cultural habits and practices that needs to be adopted. It includes prioritizing communication and collaboration with other business staekholders, continiously learning from your successes and failures and and taking an approach of rapid iteration to work toward improvements to your systems and processes.These are also the cultural habits and practices of DevOps, and they’re borrowed directly from the agile methodology, which is a project management framework.
3 pillars to DataOps -
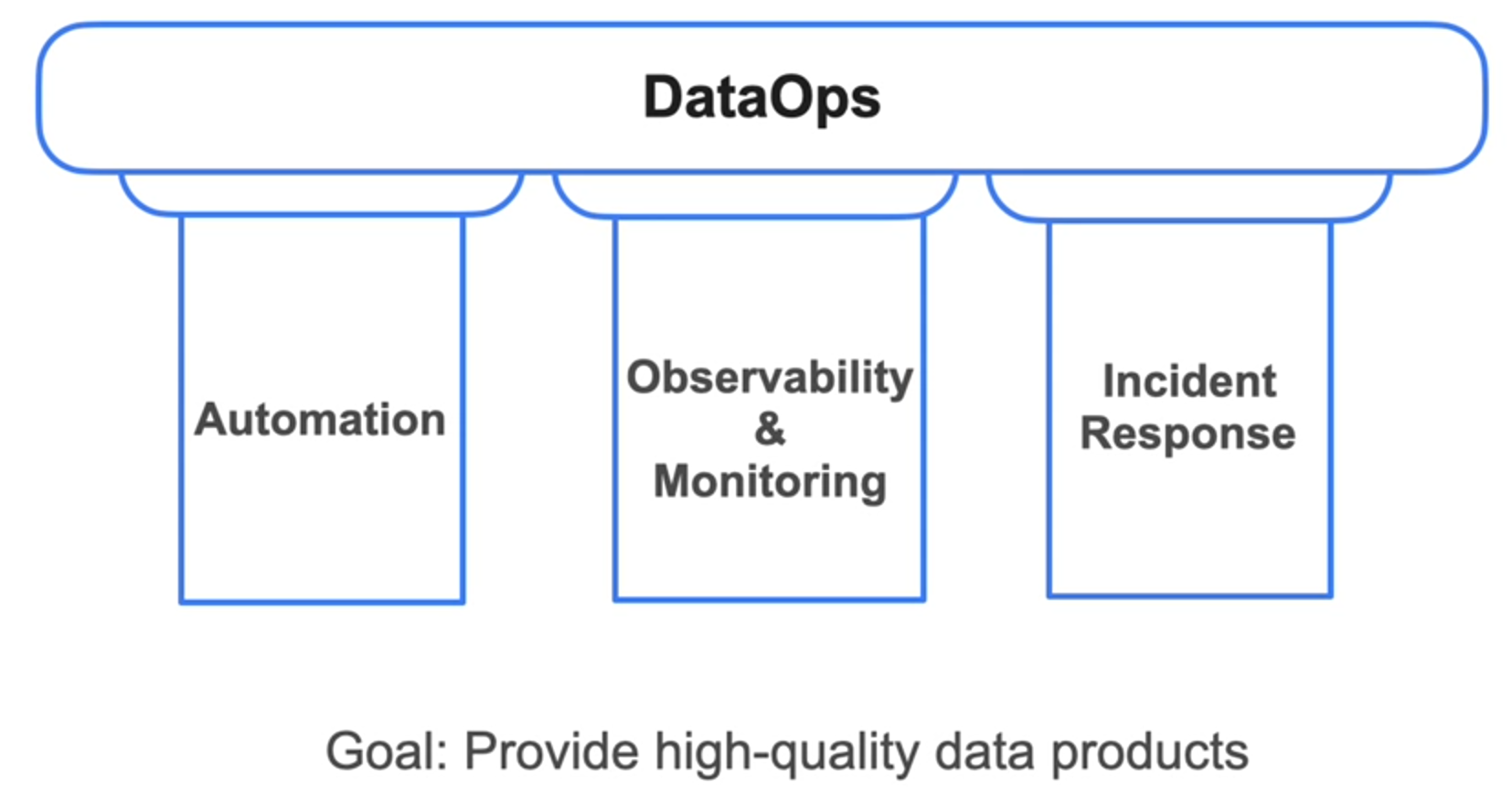
1. Automation
- Automation reduces manual processes, speeding up workflows and minimizing errors.
- Similar to DevOps' CI/CD for software, DataOps uses automation to manage changes in:
- Code and configuration .
- Data pipelines and the data itself .
- Examples of Automation:
- Manual Execution : Initially, you might manually run each stage of a pipeline.
- Scheduling : Automate tasks based on time (e.g., nightly ingestion jobs).
- Orchestration Frameworks (e.g., Airflow) : Automate task dependencies, error notifications, and pipeline development, ensuring tasks execute in the right sequence.
2. Observability and Monitoring
- Every data pipeline will fail eventually. Observability ensures you detect issues early rather than relying on stakeholders to flag problems.
- Without monitoring, bad data can persist in reports or dashboards for months, leading to wasted time, money, and stakeholder mistrust.
- Use monitoring tools to:
- Track data quality and pipeline performance.
- Identify failures in real-time.
3. Incident Response
- Incident response involves quickly identifying and resolving failures in your pipelines.
- Key practices:
- Proactive Problem-Solving : Address issues before stakeholders notice them.
- Blameless Collaboration : Foster open communication among team members to resolve incidents efficiently.
- Effective incident response relies on strong observability and monitoring.
Orchestration
Orchestration in data engineering ensures that all the tasks in a data pipeline are coordinated and executed efficiently, much like a conductor directing an orchestra. It spans the entire data engineering lifecycle and is a core component of DataOps.
The Role of Orchestration
- Coordination of Tasks :
- A data pipeline has multiple tasks (e.g., data ingestion, transformation, storage).
- Orchestration ensures these tasks execute in the correct order and handle dependencies effectively.
- Manual Execution :
- Early-stage data pipelines may involve manually triggering tasks, which is useful for prototyping but not sustainable for production systems.
- Scheduling :
- Automate tasks to run at specific times (e.g., nightly ingestion jobs).
- Challenges:
- Failures in upstream tasks can disrupt downstream tasks.
- Fixed schedules may result in incomplete or stale data if tasks take longer than expected.
Modern Orchestration Frameworks
Previously available only to large enterprises, orchestration frameworks are now accessible to teams of any size thanks to open-source solutions like:
- Apache Airflow : The most widely used framework.
- Dagster , Prefect , Mage : Newer frameworks with advanced features.
Key Features :
- Task Dependencies : Define dependencies so downstream tasks wait for upstream tasks to complete successfully.
- Event-Based Triggers : Start tasks based on specific events (e.g., new data arrival).
- Monitoring and Alerts : Set up alerts for task failures or delays.
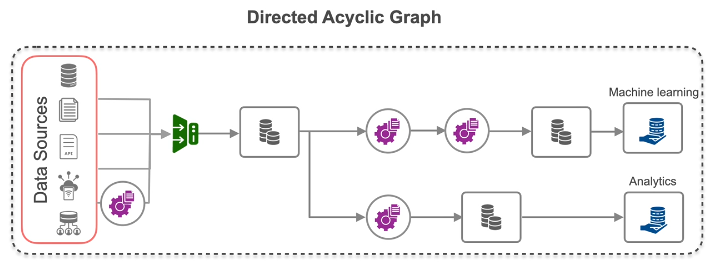
- DAG Representation : Represent pipelines as Directed Acyclic Graphs (DAGs)
-
- Directed : Data flows only in one direction.
- Acyclic : No loops; data doesn’t return to previous steps.
- Graph : Nodes represent tasks, and edges show the flow of data.
Data Engineering Lifecycle on AWS
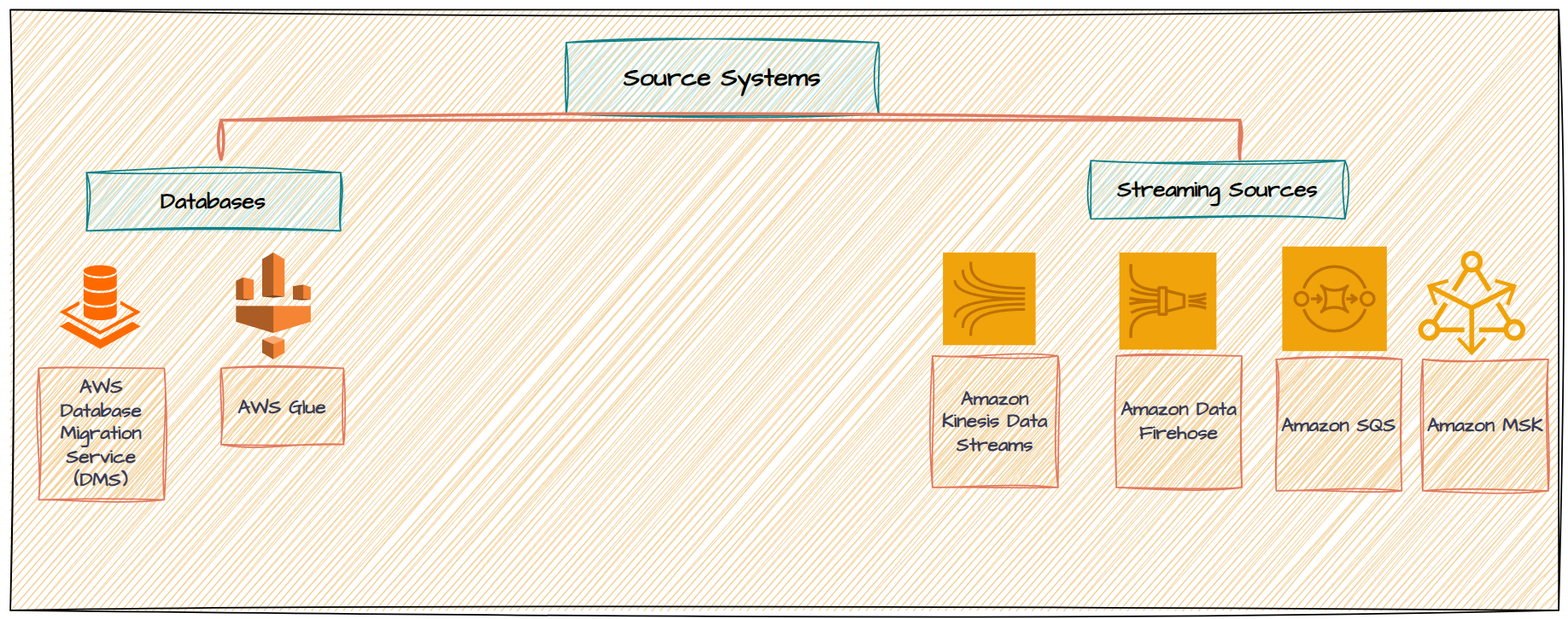
Source Systems
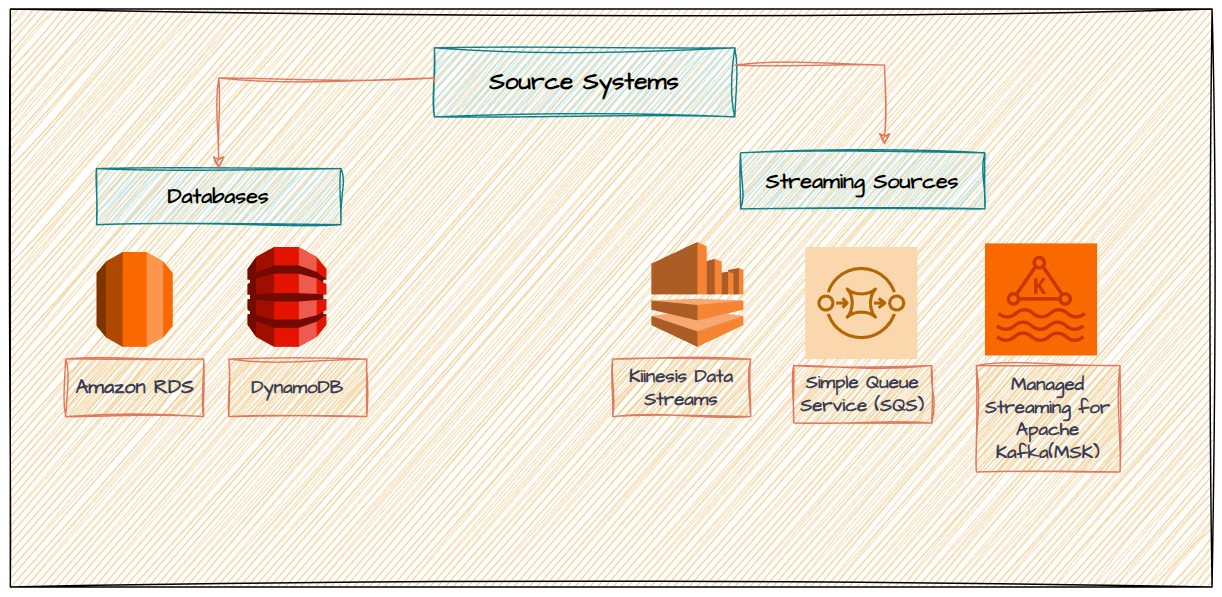

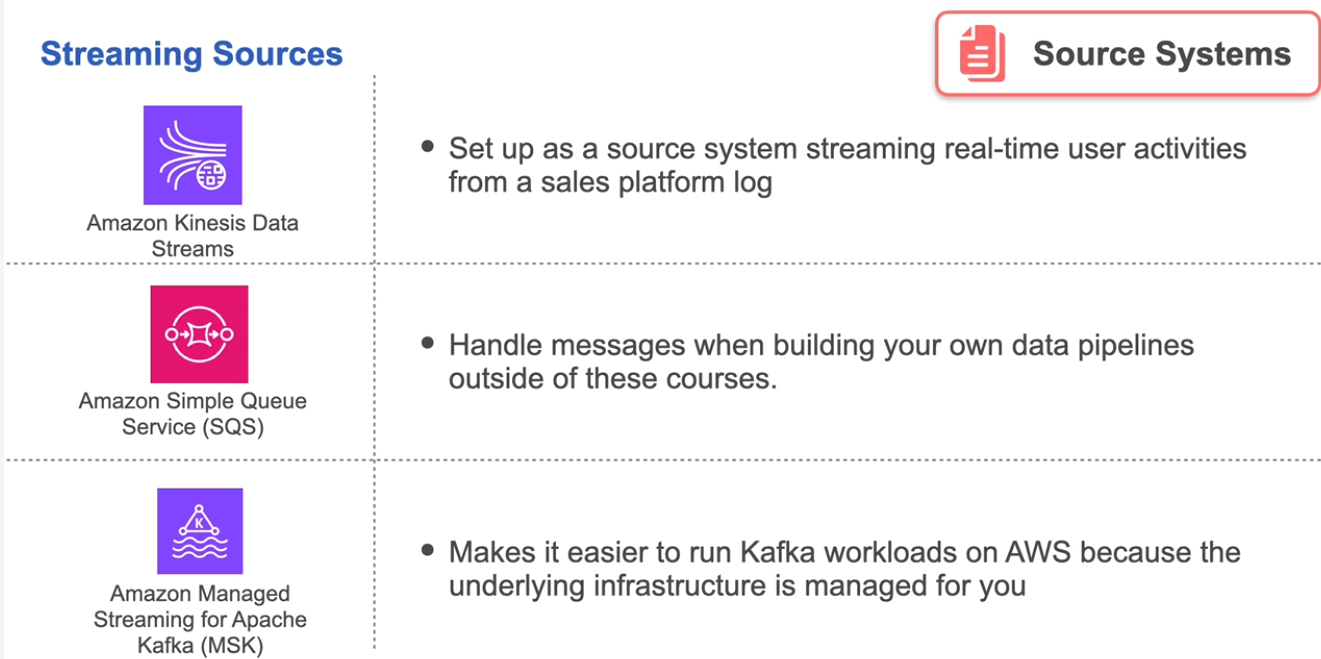
Ingestion
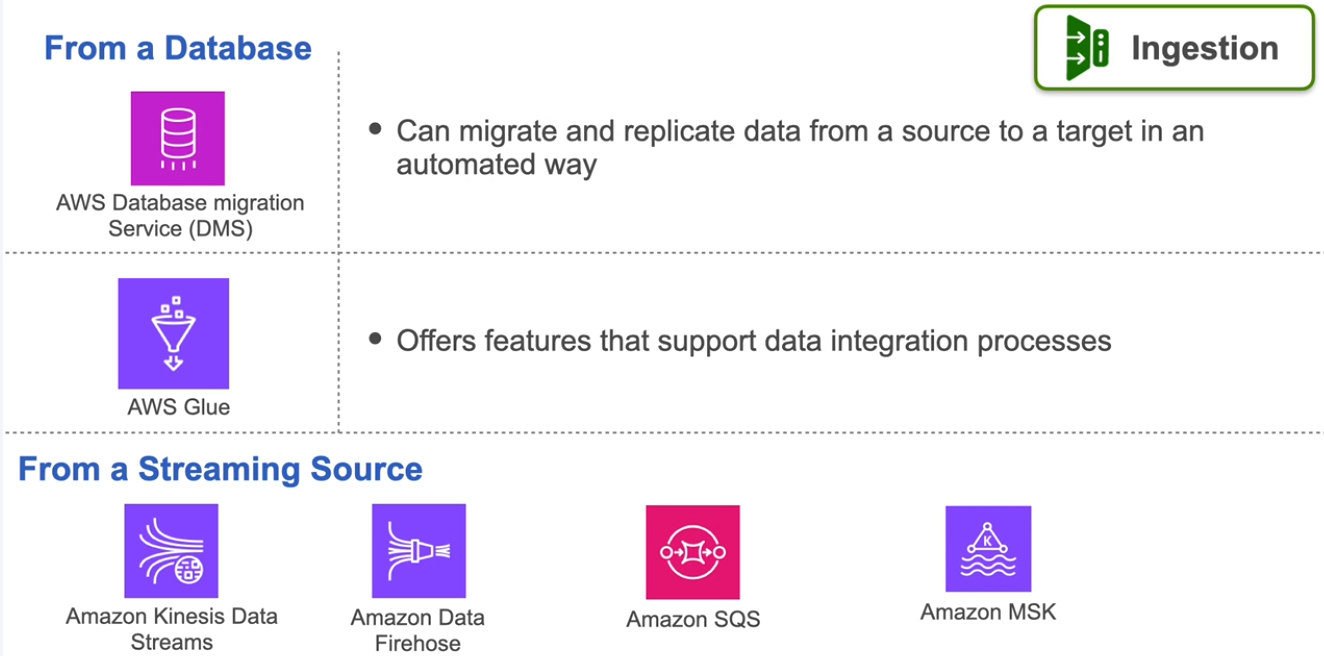
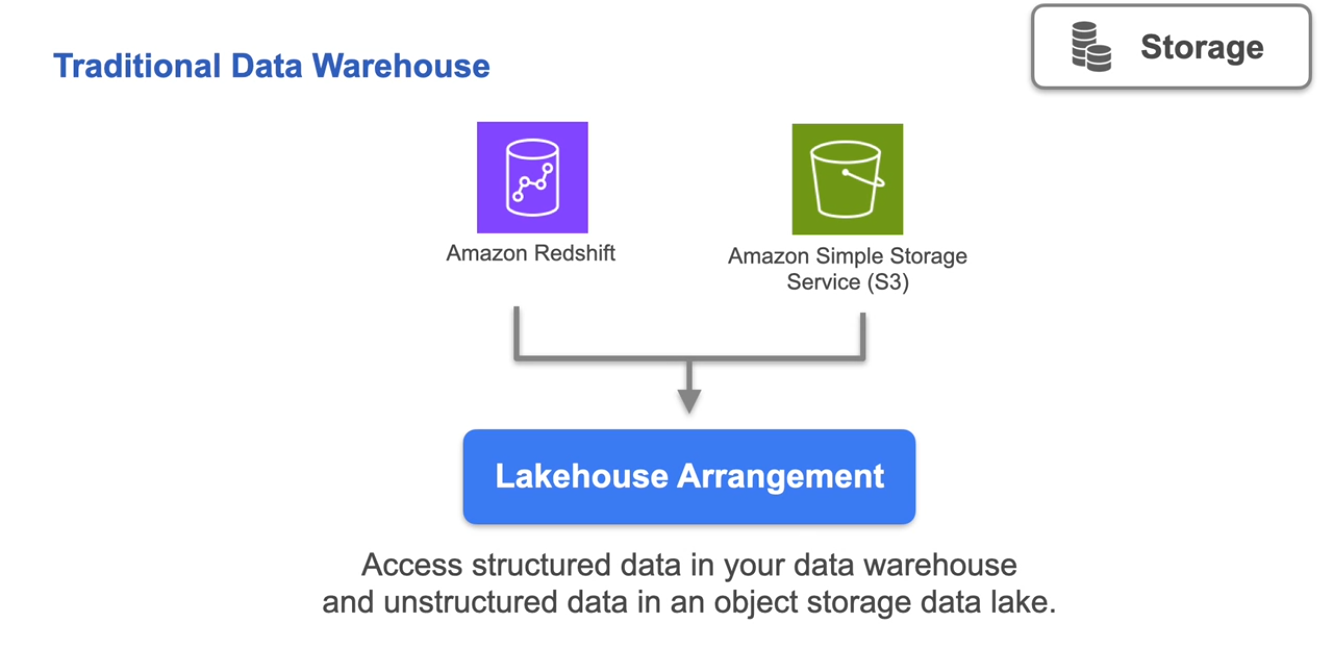
Storage
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Transformation

Serving